I've recently been investigating interest levels in a small application that spins up master/replica MySQL servers (with back-ups, yadda yadda yadda).
Tangentially from this, I've also gotten a few questions about how such a set would work within Amazon's Managed Relational Database Service (RDS).
Amazon has a few concepts going on which makes the picture of how everything works together a little hazy at first. Here's my attempt at clearing up how the RDS service works.
Regions and Availability Zones
First, we should cover Regions vs Availability Zones.
AWS has ~11 regions. These are separate physical locations, very geographically distant.
For example, there is:
- US-East (N. Virginia)
- US-West (N. Cali & Oregon)
- EU-West (Ireland)
- AP-Southeast (Singapore, Sydney)
- and 6 others spread across the world
Each region has multiple Availability Zones (AZ). These zones are also physically different locations, but within the same general geographical area.
These availability zones are close together and connected by high-bandwidth networks, making the network latency between them pretty low.

In theory, us-east-1d can explode without affecting us-east-1e. However, practical experience says otherwise. About twice a year, we've seen large service interruptions which tend to affect entire regions (looking at you, us-east-1).
Some generalisms about regions and availability zones:
- Network connections between AZ's are usually quite fast, often fast enough to not worry about inter-AZ communication for most web applications. YMMV.
- Network connections between Regions can/will be slower due to geographical distance.
- Services (EC2, SES, etc) have different prices in different regions. Us-east-1 tends to be the cheapest (but most over-used).
With that out of the way, let's actually talk about RDS. Specifically, we'll talk about MySQL. Some details will be different per database.
The Basics
RDS is a managed database service. In return for paying an arm and a leg (although it's still cheaper than hiring a human being!), you get a managed database.
Server Size
One of your first decisions in setting up an RDS instance will be to decide how large the database is. Because the cheaper T instance type uses a system of CPU credits to minimize cost for burst work loads, I tend to stay away from it with RDS, which often has a more consistent work load. The T series of instances will throttle available CPU after credits are used.
Of course, depending on your work load, using a server type that's better for burst usage can make sense.

I like the m3.large (2 vCPU, 7.5GiB RAM) instance size to start with, although that's probably overkill for small/starting applications.
If you're in a position where you can fit your application and database workload into a 1-2 CPU server/2-4GB RAM, I don't suggest using AWS at all. Linode/Digital Ocean is much more cost-effective and simple.
In us-east-1, with 100gb of storage, that's ~$144/mo (not counting bandwidth usage) with no failover (Multi-AZ) nor replication.

For this price, you get:
- A managed database instance that (probably?) won't suffer too many issues.
- Backups back for n (selectable) days. These allow point-in-time recovery, granularity up to the second ?!

Multi-AZ
The next decision to make is whether or not to enable a Multi-AZ deployment. Amazon pushes hard on this in their documentation, but this is not replication. At least, not the replication you're thinking of.
Multi-AZ is about two things:
- Durability
- Fast failover
In addition to Amazon's default durability metrics, Multi-AZ deployments will make a synchronous copy of your database to another AZ within the region you're creating the database.
If your RDS instance is in us-east-1d, the copy might end up in us-east-1c.
Synchronous is the interesting part there. Amazon is guaranteeing that any change that is made on the primary database is also made in the copy. This isn't something that a database will usually guarantee without a lot of potential slowdown, as it's typically done via transactional locking - the database waits for all replicas to report that it's completed the transaction before moving on to the next query.
Since AZ's in Amazon are physically different locations, my best guess on how this is accomplished is by proxying TCP connections so they go to both AZ's at once. I don't think this is a copy done on the hard disk level (e.g. raid array) due to the physical locations being different.
What's it good for?
The best reason for this setup is so your application can failover fast in the event that the AZ goes down. According to the opening announcement of Multi-AZ (from 2010), this failover takes ~3 minutes.
Amazon takes care of this for you - the database host doesn't even change, so your application should switch over without too much interruption. Other than that phantom 3 minutes, I suppose. I haven't had this happen to me yet to find out.
The other nice thing is that backups are done on the replica database, so it doesn't cause any IO congestion on your production database.
Note that you can't use this replica unless the production server fails over.
Also, this considerably increases your cost. Selecting this brings it up to ~$293/mo, a little more than double the cost.

Considerations
The only thing to watch out for here is if you are putting RDS in the same AZ as your application servers. If your application servers are also down, then having a database failing over to another AZ isn't really going to help you.
That's why it's also recommended to use at least 2 AZ's for any application. This means using a load balanced environment for any application where it isn't OK for it to go down once in a while.
I don't really worry about network lag between AZ's, and AWS is essentially setup with the assumption that you will not either. They want you to use multiple AZ's for RDS and for your applications.
Read Replication
RDS does indeed offer replication that you can use to distribute read queries (there isn't any option for multiple write replicas, because databases are hard).
Like regular old database replication, this is asynchronous. Your replica is not guaranteed to be up to speed with your master database.
Other than the obvious benefits of distributing expensive read queries, AWS does some other smart things. For example, databases go into maintenance occasionally for updates. In Multi-AZ deployments, the database can fall over to a backup. If you use replication, your application can continue to make read queries to a replication database.
You need to be careful, however, as it's possible to accidentally send write queries to the replication database (I believe this is an aspect of MySQL, were a super user can override a read-only configuration).
Read replication databases can be promoted to a "regular" database. In fact, this is how you get cross-region replication with RDS. For "serious" (important, larger budget) deployments, this may be an important step in keeping your application available and/or keeping low response time for read queries around the world.
Note that replication lag will increase using cross-region deployment, due to the large geographic distance between regions.
Read replicas are charged just like a regular database instance, so if you're using a database with Multi-AZ and one read-replica, you're paying ~438/mo, roughly triple what you pay for just one instance.

Although you can save big money overall by using reserved instances:
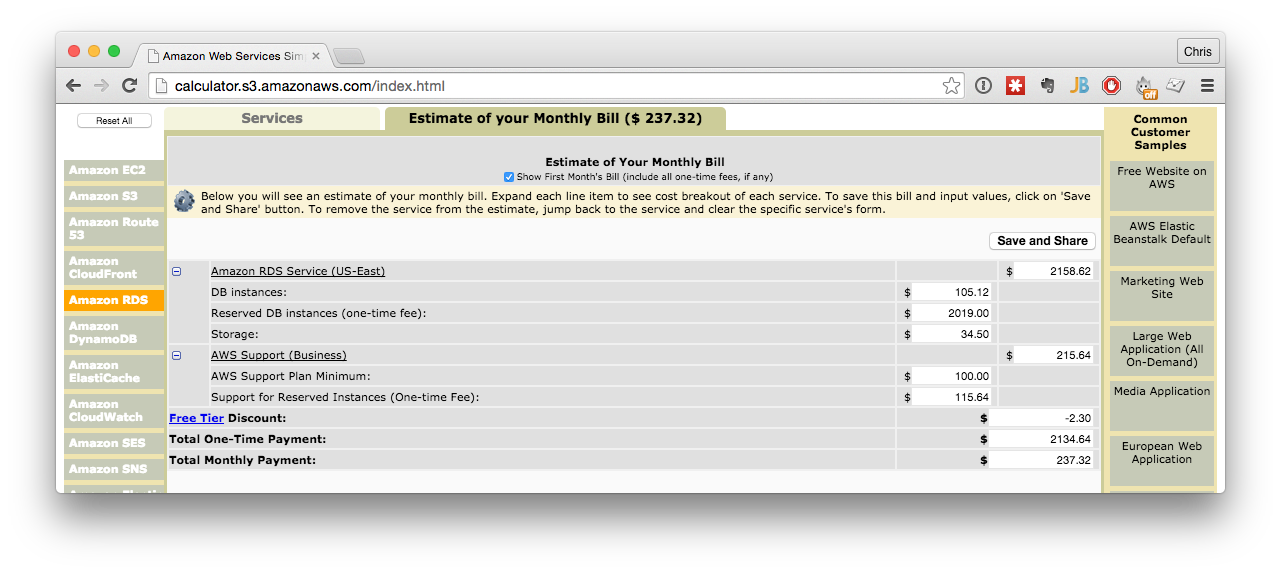
Let's see that math for one instance, with Multi-AZ and a read replica:
- $438.46/mo for 3 years = $15,784.56
- Reserved for 3 yrs with partial up-front payment is $237.32/mo + $2,158.62 = $10,702.14
If you know you'll have the database for that long, reserved instances gives you a significant savings. Keep in mind you can, if workload and compliance permits, create many individual databases with an RDS instance as well.
The rent is too damned high!
Those plugged into the Entrepreneurial Scene™ may "know" that products "should" (all those air quotes!) be priced based on the value the product brings:
- Revenue brought in
- Time savings
- Money savings
AWS, in theory, replaces the technical know-how of a consultant or full-time DBA, and Amazon charges based on (under!) that value.
With RDS, you're paying to relieve administrative burden and disaster recovery. It's not cheap.
Side note, If you're interested in a less expensive, but unmanaged MySQL-optimized, backup and (eventually) replication service, sign up here to let me know! The idea with this application is it will allow you to better manage your own MySQL instances, while taking advantage of many RDS-like features.